Which AI Is Better? A Practical, Evidence-Based Comparison for AI Agents
An analytical side-by-side guide for developers and leaders. Learn how to evaluate which ai is better for your tasks, data, governance, and ROI with objective criteria and actionable steps.

The short answer is: there isn’t a universal 'better' AI; the winner depends on your goals, constraints, and workloads. In many real-world settings, a domain-agnostic, highly customizable agent with strong orchestration and governance beats a generic, one-size-fits-all model for long-running processes. The Ai Agent Ops team emphasizes that better means more aligned with your task, data, latency tolerances, and safety requirements.
Why the Question 'Which AI Is Better' Matters for Builders and Business Leaders
According to Ai Agent Ops, the question of which ai is better drives architecture, governance, and ROI decisions. The lowercase phrasing 'which ai is better' signals a broader evaluation rather than a single product sale. For developers and executives, the goal is to tie capability to task, data availability, latency constraints, and risk tolerance. In this article, we explore objective criteria, practical trade-offs, and decision patterns that help you pick the right AI approach for your use case. By grounding the discussion in real-world constraints, we help you avoid vendor hype and focus on outcomes that matter to your organization.
This article targets engineers, product owners, and business leaders who need a defensible path to choosing between general-purpose AI and domain-specific AI orchestration. You’ll see practical evaluation methods, sample scenarios, and a framework that translates abstract claims into measurable value. The goal is to reduce guesswork and align decisions with your organization’s risk profile and operational realities.
To keep the discussion concrete, we tie rules of thumb to observable signals like data readiness, latency budgets, and governance controls. Whether you are piloting a new AI workflow or rearchitecting an entire automation platform, this guide helps you map outcomes to concrete, testable criteria.
How We Define 'Better' in AI Agents
In this framework, better means reliable execution, measurable impact, and safe, compliant operation over time. We evaluate agents along dimensions like task success rate, latency, data governance, and maintainability. The aim is to avoid blinding optimisms about capabilities and instead quantify outcomes that matter to teams building production systems. Our approach combines controlled experiments, real-world usage metrics, and governance checks to produce a balanced view of what works where. Importantly, better is context-dependent: a solution that excels in one domain may underperform in another. This section explains the criteria Ai Agent Ops uses to compare approaches rather than marketing claims.
We start with outcome-based metrics and then add process controls: versioning, observability, and rollback capabilities. By separating capability claims from operational reality, you can build decision criteria that survive vendor changes and data shifts. The practical upshot is a framework you can apply repeatedly as teams mature and use cases evolve.
Finally, we emphasize that 'better' should translate into measurable business value, not just improved user experience. Without a solid metric set, any comparison risks becoming a recitation of features instead of a decision grounded in outcomes.
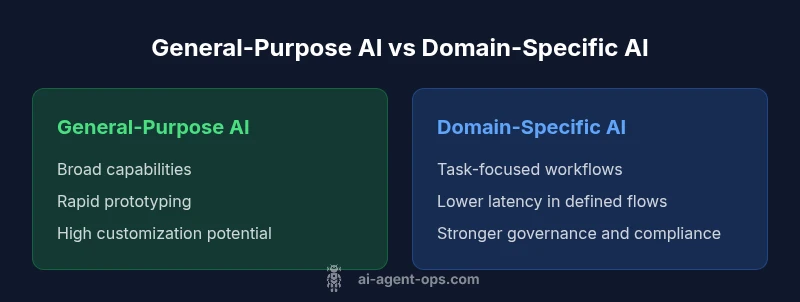
The Key Differentiators: General-Purpose vs Domain-Specific Agents
Two archetypes dominate discussions about which ai is better: general-purpose agents with broad task coverage and domain-specific, orchestrated agents tuned for particular workflows. General-purpose agents offer flexibility, rapid prototyping, and the ability to adapt to new tasks without rebuilds. Domain-specific agents, by contrast, deliver higher reliability in fixed processes, lower latency, and tighter governance because they are integrated with domain data sources and SLAs. Understanding these differentiators helps teams align with business goals, whether the priority is experimentation and scale or predictability and compliance.
In practice, organizations often start with a general-purpose backbone and layer domain-specific modules on top to capture both breadth and depth. This hybrid approach lowers risk while preserving agility. The key is to define where the domain boundary lies: which data sources, which SLAs, and which governance controls must be enforced across tasks. When you document these boundaries, you reveal the true cost and value of each archetype, making the choice explicit rather than implicit.
Performance, Latency, and Cost: Practical Trade-offs
Performance is not a single metric; it blends accuracy, speed, and consistency under load. A general-purpose agent may incur higher latency on complex tasks, because it reasons across diverse contexts. A domain-specific agent can optimize for throughput and predictable response times by narrowing scope and preloading domain knowledge. Cost considerations include compute, data transfer, storage, and maintenance. While a general-purpose setup can be cheaper to start, scaling governance and monitoring often makes long-term costs comparable to domain-specific approaches. In practice, the best choice balances required throughput with acceptable cost and risk.
Latency budgets are a practical lens: if you need sub-second responses for customer interactions, design for domain-specific latency, caching strategies, and specialized data pipelines. If your tasks are exploratory and require flexibility, plan for higher latency tolerance and incremental integration. Finally, consider the total cost of ownership, including personnel, training, and platform fees, and verify it against projected business impact through a simple ROI model. This frame helps teams avoid over-optimizing for one metric at the expense of overall value.
Governance, Safety, and Compliance Considerations
As organizations deploy AI agents, governance, safety, and compliance become core differentiators. General-purpose systems require robust policy enforcement, data lineage, and audit trails to remain compliant across use cases. Domain-specific agents often benefit from tighter data boundaries, clearer ownership, and SLA-driven monitoring. Yet both types demand guardrails, prompt provenance, and explainability to support accountability. Ai Agent Ops recommends a guardrail-first approach: define what data can be used, how outputs are reviewed, and how deviations are detected and corrected.
Regulatory considerations vary by industry, but the pattern is consistent: you must translate abstract compliance requirements into concrete operational controls. That means access controls, data minimization, logging, and observable decision points. Establish a governance playbook before you scale, and map who is responsible for each stage of the AI lifecycle—from model updates to incident response. When governance is baked in, it becomes a competitive differentiator rather than a compliance cost.
Finally, safety is not a one-time checkbox. It requires ongoing evaluation of model behavior, prompt injection risks, and monitoring for drifts in outputs. A proactive, cross-functional safety program is essential for trustworthy AI that can be adopted at scale.
Evaluation Frameworks: Metrics and Testing Approaches
A rigorous evaluation begins before code is written. Define success metrics aligned with business goals: task completion rate, mean time to resolution, data privacy incidents, and operator effort required. Use A/B testing, shadow deployments, and controlled pilots to compare options fairly. Track both lead indicators (latency, throughput) and lag indicators (uptime, user satisfaction). Documentation, versioning, and rollback plans are essential to prevent production risk. Our framework also emphasizes post-deployment monitoring and continuous improvement loops to keep the chosen AI relevant as data and workflows evolve.
In practice, create a measurement plan that ties back to a business outcome—such as reduced manual handoffs or faster issue triage. Ensure your tests cover edge cases and regulatory requirements, not just average performance. Use synthetic workloads to stress-test governance controls and recovery procedures. Finally, harmonize your evaluation with your product roadmap so that what you learn accelerates future iterations rather than becoming a sunk cost.
Implementation Realities: Data, Privacy, and Maintenance
Real-world implementation involves more than math: integration into existing systems, data compatibility, and ongoing maintenance. General-purpose agents benefit from flexible connectors, but require governance to prevent data leaks or policy violations across teams. Domain-specific agents reduce risk by leveraging curated data stores and clear ownership, yet demand closer collaboration with domain experts and faster update cycles. Consider the total cost of ownership, including personnel, training, and potential downtime during migrations. A phased rollout with clear milestones helps teams learn while controlling risk.
Data quality is a top determinant of success. In practice, teams should prioritize clean, well-documented data sources and robust data governance policies. You’ll also want a monitoring stack that surfaces drift, anomalies, and policy violations early. Finally, maintenance is a cross-team responsibility: product, security, legal, and data science must align on update cadences and rollback plans. Those habits turn initial pilots into scalable, reliable production platforms.
The operational reality is that AI is not a one-time build but a continuous capability that evolves with your data and rules. Plan for iterative improvements, not a single release, and you’ll reduce risk and increase the odds of sustained value.
Decision Guidelines: Choosing the Right AI for Your Context
To decide which ai is better for your organization, start with a precise problem statement and success criteria. Map tasks to capabilities: generalizable tasks to a general-purpose agent, highly repetitive or regulated tasks to a domain-specific agent. Build a lightweight prototype to test critical assumptions, then scale with governance and monitoring. Finally, consider a hybrid approach: combine a general-purpose backbone with domain-specific modules to capture breadth and depth. This structured approach gives teams a reproducible path from pilots to production.
If you must choose now, pair a minimal viable general-purpose scaffold with a domain-bound data layer and a governance charter. This lets you prove the core business value quickly while preserving the option to tighten domain controls as you scale. The practical takeaway is to design decisions that can be audited, rolled back, and extended without tearing down the entire system.
mainTopicQuery2ita_ignored_placeholder text
Comparison
| Feature | General-Purpose AI | Domain-Specific/Orchestrated AI |
|---|---|---|
| Primary purpose | Broad capabilities across tasks | Task-focused workflows with domain data and SLAs |
| Customization depth | High; modular, pluggable components | Medium; scoped to a domain, with limited scope |
| Latency and throughput | Variable; depends on prompts and context | Lower and more predictable for defined flows |
| Data handling & privacy | Flexible governance; requires policy controls | Tighter data boundaries; easier compliance |
| Cost and resource usage | Variable, scalable with usage | More predictable budgets; potential higher upfront |
| Maintainability | Ongoing integration and tuning | Easier maintenance within domain; specialized knowledge |
| Best for | Experimentation across tasks; rapid prototyping | Fixed processes with SLAs and governance |
Positives
- Flexible and adaptable across teams and tasks
- Supports rapid prototyping and experimentation
- Strong ecosystem and tooling for integration
- Easier to start with for multi-functional agents
What's Bad
- Higher variability in performance across tasks
- Potential ongoing costs with scale
- Requires governance to manage data and safety risks
Domain-specific, orchestrated AI generally delivers better ROI for defined workflows, while general-purpose agents excel in breadth and experimentation.
If your tasks are well-defined and require reliable SLAs, domain-specific AI provides clearer value. General-purpose AI is better when you need versatility and rapid exploration. A hybrid approach often yields the best of both worlds.
Questions & Answers
What does 'better' mean when comparing AI systems?
Better depends on the task, but it typically means reliable performance, safety, and measurable business value over time. Define success metrics tied to your goals and test those signals in production-like scenarios.
Better means AI that reliably hits your goals, stays safe, and delivers real value; measure with clear metrics and tests.
Can a general-purpose AI outperform domain-specific AI in every case?
Not in every case. General-purpose AI offers breadth and rapid prototyping, but domain-specific AI often wins on reliability, speed, and compliance for defined workflows.
Usually not. It depends on the task and regulatory needs.
How should organizations test AI options before committing?
Use controlled pilots, A/B testing, and shadow deployments with explicit success criteria and rollback plans. Pair technical metrics with business outcomes to ensure alignment.
Run small pilots with clear goals and safe rollback plans.
What are common hidden costs when scaling AI agents?
Compute and data usage grow with adoption, governance overhead increases, and maintenance or downtime during updates can add unexpected expenses.
Costs rise with usage and governance needs.
Is there a single best AI for every industry?
No. Industries have different data, regulations, and workflows; the best choice varies by domain and risk appetite.
No—it's domain-specific.
What metrics matter most when evaluating AI performance?
Look at task success rate, latency, accuracy, data governance, and operator effort. Include safety and reliability as core metrics.
Key metrics are accuracy, speed, and governance.
Key Takeaways
- Define task scope before selecting an AI type
- Establish SLA, latency, and governance early
- Use a structured, apples-to-apples evaluation
- Consider hybrid models to balance breadth and depth
- Pilot with phased rollouts to reduce risk